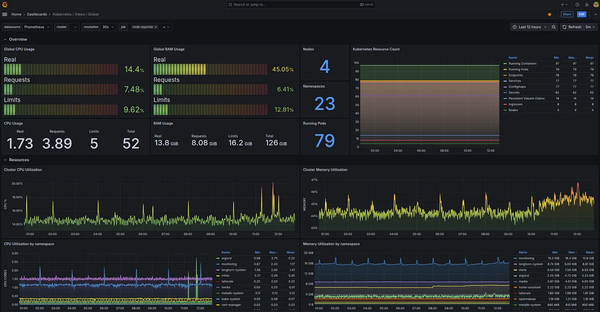
![]()
Hemos tenido el placer de asistir a la reunión de Mayo de Sudoers donde Roger Torrentsgenerós expuso Keepalived y Tomàs Núñez explicó Cassandra para sysadmins.
Ya hablamos de Keepalived. Y Cassandra se nombró muy brevemente aquí, pero sin entrar en muchos detalles. Así que vamos a aprovechar para hacer un resumen de la presentación sobre Cassandra.
Como ya sabéis Cassandra es una base de datos NoSQL descentralizada. Está diseñada para trabajar con grandes volumenes de datos y permite escalar horizontalmente de una manera muy fácil.
Está basada en Google Bigtable y Amazon Dynamo, fue desarrollada inicialmente por Facebook. Des de febrero de 2010 es un Top Level Project de Apache y la última versión es la 1.2.5.
Actualmente es un projecto con una comunidad muy activa y existen diversas compañías que se dedican a dar soporte, como por ejemplo Datastax. Grandes compañías tienen Cassandra en sus entornos de producción: Facebook, Twitter, Netflix, Digg, Groupalia, etc.
Los puntos fuertes de Cassandra son:
- Las escrituras son realmente rápidas (3000x respecto a MySQL).
- Al ser descentralizada no tiene un Single Point of Failure.
- Alta disponibilidad viene de serie.
- Escala horizontalmente.
- Requiere de muy poca administración.
- Está pensada para correr sobre hardware barato.
Respecto al modelo de datos destacar que cada objeto tiene un ID y una serie key-value-timestamp. Al ser un modelo ‘sparse’ esto le da gran flexibilidad ya que no todos los elementos de una tabla deben tenen los mismos atributos e incluso se puede alterar el número de atributos sin bloquear la tabla o tener que parar el servicio.
Respecto a la arquitectura decir que se basa en un modelo DHT (Distributed Hash Table) donde los nodos se distribuyen en forma de anillo y cada nodo es el reponsable principal para una partición y el responsable secundario para una o más particiones (dependiendo del factor de replicación que es configurable). También es posible configurar la arquitectura de manera que sea multirack o multidatacenter.
Gracias al proceso de Gossip, todos los nodos saben en todo momento los nodos disponibles, su carga y si están bajo mantenimiento o la versión de Cassandra que están corriendo.
Como ya hemos comentado las escrituras en Cassandra son muy rápidas, ya que no se preocupa de recuperar el valor (si existe) para actualizarlo, sino que escribe directamente como si el valor fuese nuevo. Esto hace que en el momento de la lectura, se tengan que recoger los valores y ver cual es el más reciente.
Como curiosidad decir que se puede definir índice secundarios y des de la versión 0.8 hay soporte para contadores.
Existe una herramienta para el mantenimiendo y admininistración de los nodos llamada nodetool, recomiendo echar un vistazo a la wiki de Apache para ver los detalles de esta versátil herramienta.
Una manera muy sencilla de hacer una copia de seguridad es definir un cluster de backup con un nodo donde se almacenaránn todos los datos, y hacer la copia de este nodo.
La parte más interesante de la presentación fue cuando el ponente hizo gala de su dilatada experiencia con Apache Cassandra y nos explicó una serie de errores frecuentes y algunas optimizaciones. Recomiendo encarecidamente su lectura http://www.tomas.cat/blog/en/cassandra-frequent-mistakes.
Tan solo felicitar a Tomas por su excelente presentación.
Por último podéis encontrar la presentación original aquí.
Espero que lo disfrutéis 😉
Lorenzo Cubero – CloudAdmin